Paper Notes: Recursive Multi-Agent Systems
## Why these papers, and what you'll learn Imagine you're building a team of specialists to solve a hard problem — a mathematician, a biologist, a data analyst. The obvious bottleneck isn't individual expertise; it's the overhead of getting them to talk to each other. Every hand

Why these papers, and what you'll learn
Imagine you're building a team of specialists to solve a hard problem — a mathematician, a biologist, a data analyst. The obvious bottleneck isn't individual expertise; it's the overhead of getting them to talk to each other. Every handoff costs time and introduces noise. Now imagine the same problem, but some of your specialists don't speak the same language at all — one thinks in protein folding geometries, another in graph embeddings, another in plain text. How do you even wire them together? These two papers attack different facets of that coordination problem in multi-agent AI systems, each from a distinct angle.
Paper 1 — RecursiveMAS asks whether agent collaboration itself can be made more efficient by treating the entire multi-agent system as a single, iteratively refined computation. Instead of agents exchanging verbose text messages back and forth, they share compact latent states through a lightweight connector module, looping over the same agents repeatedly the way a recurrent network loops over time steps. The result is faster inference, far fewer tokens consumed, and — according to their experiments across nine benchmarks — meaningfully better accuracy. Paper 2 — Eywa addresses a different gap: most agentic frameworks assume language is the universal currency, which works fine for text tasks but breaks down the moment you need to reason over protein structures, molecular graphs, or climate simulation outputs. Eywa wraps domain-specific scientific foundation models (the kind trained on non-linguistic data) with a language-model reasoning interface, so a planner can coordinate them alongside ordinary language agents without forcing everything through a text bottleneck.
These two papers share a genuine common thread: both reject the assumption that language tokens are the right unit of exchange between agents, and both propose structured alternatives. RecursiveMAS replaces inter-agent text with latent vectors; Eywa replaces language-only agents with modality-native specialists. The architectural philosophies are different, but the underlying dissatisfaction is the same. In this post you'll build intuition for how each system works, why their efficiency claims hold up mathematically, and run a small Python experiment that demonstrates the core latent-sharing idea behind RecursiveMAS — no GPUs, no API calls required.
Recursive Multi-Agent Systems
The intuition
Here's the problem: when you have multiple AI agents collaborating to solve a hard problem, they typically talk to each other in full English sentences. Agent A finishes a reasoning step, writes out a paragraph explaining its conclusion, and Agent B reads that paragraph and starts fresh. This is the AI equivalent of two programmers collaborating by printing out their code, mailing the printout, and having the recipient retype it from scratch. The text interface is legible and flexible, but it throws away the rich internal state that the first agent had already computed.
RecursiveMAS attacks this waste directly. The analogy that fits best is a relay race with shared memory: instead of each runner passing a baton (a discrete object with limited information), imagine they pass a full mental snapshot — the exact physiological state of readiness the previous runner had built up. The next runner doesn't start cold; they start informed.
The mechanism works as follows. A set of heterogeneous agents — say a mathematician and a coder — are connected in a loop. When the first agent processes a problem, instead of outputting only text, it also produces a latent state: a high-dimensional vector encoding its internal reasoning. A small connector module called RecursiveLink translates that latent state so the second agent's embedding space can receive it. The second agent ingests both the latent state and whatever text context it needs, then produces its latent state, which feeds back into the loop. This loops multiple times — called recursion rounds — before the system emits a final answer.
Why does this matter beyond efficiency? The paper's deeper claim is that this enables whole-system co-optimization: because latent states flow continuously through the loop, gradients can propagate across agent boundaries during training. Every agent can be tuned with respect to every other agent's effect on the final output. In standard text-based multi-agent systems, the text serialization step cuts the gradient tape. Here it doesn't.
Engineers in adjacent areas — say, distributed systems or compilers — will recognize this as similar to the tension between inter-process communication via serialized messages versus shared memory: one is safe and flexible, the other is fast and richly stateful.
How the method actually works
The RecursiveLink module. At the heart of RecursiveMAS is a simple but carefully designed bridging module. Each agent in the collaboration loop produces a latent state at each recursion round . Rather than serializing to text, RecursiveLink maps it into the input embedding space of the next agent :
This is a learned linear (or lightweight MLP) projection. The projection is trained specifically so that the incoming latent state appears in-distribution to agent — meaning it looks like a normal embedding token rather than out-of-domain noise. The paper calls this "in-distribution latent thoughts generation," and it's the key to making the receiving agent process the transferred state coherently rather than treating it as garbage input.
The recursion loop. Let the agents be indexed . At recursion round , the pipeline is:
where is the problem input, is the latent from the previous agent in this round, and is the latent from the same agent in the previous round. This double dependency is what makes it recursive in two senses: across agents (spatial) and across rounds (temporal). After rounds the final agent emits a decoded text answer.
Four collaboration patterns. The paper instantiates this loop under four distinct structural patterns (described in their experiments section): sequential chains, parallel ensembles, hierarchical structures, and debate-style adversarial loops. RecursiveLink is the same module in each case — the topology differs, but the latent-sharing mechanism is identical. This modularity is a genuine architectural strength.
The inner-outer loop training algorithm. Training is the hardest part. Because agents are frozen pretrained LLMs with LoRA-style fine-tuning, and because the loop is unrolled over rounds across agents, the full computation graph can be deep and unstable. The paper proposes splitting optimization into:
- Inner loop: Forward-pass through all agents and rounds with gradients accumulated; backpropagation through RecursiveLink projections.
- Outer loop: Update of agent-specific LoRA parameters using the aggregated gradients from the inner loop.
The shared gradient-based credit assignment means that if agent 2's latent state consistently helps agent 3 produce better answers, agent 2's weights are rewarded for it — even though agent 2 never sees agent 3's output directly. This is analogous to how BPTT (backpropagation through time) in RNNs assigns credit across time steps.
Complexity claim. The paper argues that token usage scales as with latent exchange, versus for text-based MAS, where in practice (a latent state is a fixed-size vector; a text reasoning chain can be hundreds of tokens). This is the theoretical basis for the 34.6%–75.6% token reduction reported empirically.
Gradient stability. The paper includes a theoretical analysis showing that, under mild Lipschitz conditions on RecursiveLink, gradient norms remain bounded across recursion rounds — addressing the vanishing/exploding gradient concern that would naturally arise when unrolling rounds. This analysis parallels classical RNN stability results.
What the paper actually shows (with verbatim quotes)
"RecursiveMAS connects heterogeneous agents as a collaboration loop through the lightweight RecursiveLink module, enabling in-distribution latent thoughts generation and cross-agent latent state transfer."
This sentence from the abstract captures the two things that have to go right simultaneously. "In-distribution" is doing a lot of work here: if the transferred latent looks like a foreign object to the receiving model, it will likely be ignored or cause degraded outputs. The paper's training procedure is specifically designed to push the projected latents into the receiving model's normal activation range — this is tested empirically by measuring perplexity of the receiving model on transferred versus native latents, though the details of those ablations are in the experiments section.
"RecursiveMAS consistently delivers an average accuracy improvement of 8.3%, together with 1.2×–2.4× end-to-end inference speedup, and 34.6%–75.6% token usage reduction."
These numbers are reported across nine benchmarks spanning mathematics (MATH, GSM8K), science (MMLU-Science), medicine, search tasks, and code generation. Several things are worth unpacking:
The accuracy improvement (8.3% average) is measured against both single-agent baselines and standard text-based multi-agent systems. Beating text-based MAS is the more meaningful comparison — it says that latent sharing genuinely helps beyond just adding more agents.
The inference speedup (1.2×–2.4×) varies considerably across benchmarks. Tasks where text-based agents produce very long intermediate chains (like multi-step math) see the larger speedups. Tasks where intermediate text is already short see more modest gains. This makes intuitive sense: if agents weren't producing verbose outputs anyway, there's less redundancy to eliminate.
The token reduction (34.6%–75.6%) is the most striking range. The lower end corresponds to tasks that already require substantial final text output; the upper end corresponds to tasks where most tokens were previously intermediate reasoning chains now replaced by latent vectors.
The nine-benchmark evaluation is broader than many papers in this space, which is a credibility signal. The inclusion of search tasks (retrieval-augmented settings) is particularly notable because it tests whether latent sharing degrades when agents need to interface with external tools that speak only in text.
Honest critique
What the paper does well. The theoretical grounding is more rigorous than typical multi-agent papers. The stability analysis and complexity proofs are genuine contributions, not decoration. Testing across four distinct collaboration topologies with the same RecursiveLink module is a strong argument for the method's generality. The token reduction numbers, if they hold up, represent meaningful practical savings for deployed systems.
Concerns about the latent transfer assumption. The in-distribution constraint is the architectural linchpin, but it is also the biggest fragility. RecursiveLink is trained jointly with the agents, which means the projection is only guaranteed to be in-distribution for the specific pair of models trained together. In practice, you would likely need to retrain RecursiveLink any time you swap one agent for another — this limits the plug-and-play composability that makes multi-agent systems attractive in the first place. The paper does not directly address how sensitive results are to changes in agent composition post-training.
The gradient-sharing mechanism requires joint training. The inner-outer loop algorithm is genuinely clever, but it means you cannot simply bolt RecursiveMAS onto existing pretrained agents without a fine-tuning phase. This is a non-trivial cost in practice — most organizations have heterogeneous fleets of models they want to compose without retraining.
Benchmark overlap with existing work. GSM8K and MMLU are well-studied benchmarks where many baselines exist. The 8.3% average improvement is significant, but the variance across benchmarks and the specific baseline configurations matter. Without seeing the full results table, it's hard to assess whether the gains are consistent or driven by strong performance on a few easier benchmarks.
Open questions. How deep can the recursion go before instability sets in despite the theoretical bounds? The Lipschitz conditions assumed in the stability proof may not hold tightly for large LLMs. What happens when agents have very different parameter scales (e.g., a 7B model next to a 70B model)? Does RecursiveLink's projection remain well-conditioned?
Heterogeneous Scientific Foundation Model Collaboration
The intuition
Most multi-agent AI frameworks assume that every agent speaks the same language — literally. Agents exchange text, the planner issues text instructions, tools return text results. For question-answering, coding, or web search, this is fine. But consider a drug discovery pipeline that involves: predicting protein structure (a geometry problem), predicting molecular binding affinity (a graph neural network problem), and synthesizing the results into a clinical recommendation (a language problem). Forcing the first two steps through a text interface means throwing away the output representations that specialized models spent enormous compute learning — it's like asking a structural biologist to summarize their molecular dynamics simulation as a paragraph before the chemist looks at it.
Eywa's answer is to give specialized foundation models a language-model-based reasoning interface without requiring them to speak language natively. The analogy here is a professional interpreter working in real time: the structural biologist doesn't learn to speak chemistry; instead, a skilled interpreter sits between them, translating the biologist's outputs into a form the chemist can act on while preserving the technical content.
Concretely, Eywa wraps a domain-specific model — a protein structure predictor, a molecular property predictor, a climate simulator — with an LLM-based interface layer. The LLM learns to invoke the specialist model, interpret its non-linguistic outputs (embeddings, coordinates, probability distributions), and integrate those interpretations into a broader reasoning chain. The planner, which coordinates the overall workflow, sees a uniform agent API and doesn't need to know whether it's talking to a language model or a protein folding model.
The paper offers three deployment modes: a single-agent wrapper (EywaAgent), a drop-in replacement for agents in existing MAS pipelines (EywaMAS), and a planner-coordinated multi-modal orchestra (EywaOrchestra). Evaluated across physical, life, and social sciences, Eywa improves performance on tasks involving domain-specific data while reducing how much the system has to rely on language-only reasoning.
How the method actually works
The fundamental design choice. Standard agentic LLM systems treat tools as black boxes that return text. A web search tool returns text snippets; a calculator returns a number as text. Eywa's observation is that scientific foundation models return structured non-linguistic objects — protein coordinate tensors, molecular graph embeddings, time-series forecasts — and that collapsing these to text before the LLM reasons over them discards information.
The fix is an augmentation layer on top of each domain-specific model. Formally, let be a specialist model that takes domain input and produces an embedding or prediction in a non-linguistic space. Eywa adds a lightweight adapter:
that maps the specialist's output into the LLM's token embedding space. The LLM then reasons over as if it were part of its context — not as a text description of the output, but as a direct latent representation. This is structurally similar to how vision-language models ingest image patch embeddings alongside text tokens.
EywaAgent. The simplest deployment. A single LLM is augmented with the ability to invoke one or more specialist models and receive their outputs as projected embeddings. The LLM's attention mechanism can then attend to specialist outputs alongside text. This serves as a drop-in replacement for a single-agent pipeline on tasks involving specialized data.
EywaMAS. For multi-agent settings, each traditional agent in an existing MAS framework can be replaced with an Eywa-augmented agent. The communication protocol between agents remains text-based (preserving compatibility with existing orchestrators), but each agent's internal reasoning is enriched by specialist model outputs. This is the "drop-in replacement" claim from the abstract.
EywaOrchestra. The most complex configuration. A planner LLM dynamically decides which agents to invoke — traditional language agents or Eywa agents — based on what the current task requires. This requires the planner to have some representation of each agent's modality specialty. The paper frames this as a planning problem: given a complex task that spans, say, genomics data and economic time series, the planner decomposes the task into subtasks and routes each to the appropriate agent type.
Handling heterogeneous modalities. The key engineering challenge is that different specialist models have very different output spaces. A molecular property predictor might output a scalar; a structure predictor outputs a 3D coordinate tensor; a graph neural network outputs a node embedding matrix. Eywa uses modality-specific projection heads (one per specialist model type) that all map into the same LLM embedding dimension. These projections are learned — either fine-tuned from scratch or adapted from pretrained cross-modal components where available.
What the paper actually shows (with verbatim quotes)
"Eywa is to augment domain-specific foundation models with a language-model-based reasoning interface, enabling language models to guide inference over non-linguistic data modalities."
This framing is worth dwelling on. The direction of guidance is deliberate: the LLM guides the specialist, not the other way around. The specialist still does what it was trained to do — predict protein structures, model molecular binding — but the LLM determines when to invoke it, what input to pass, and how to integrate the output into the broader reasoning chain. This preserves the specialist's training distribution (you're not fine-tuning the protein folding model) while extending its usability into agentic pipelines.
The practical implication is that Eywa requires minimal modification to existing specialist models. Organizations that have already trained domain-specific foundation models can participate in agentic systems without retraining, which is a real deployment advantage.
"Experimental results demonstrate that Eywa improves performance on tasks involving structured and domain-specific data, while reducing reliance on language-based reasoning through effective collaboration with specialized foundation models."
The second clause — "reducing reliance on language-based reasoning" — is the operationally interesting claim. The paper is saying that tasks which previously required the LLM to approximate specialist knowledge via language (e.g., describing what a protein structure might look like based on sequence alone) can now be handled by actually invoking the specialist. This is a qualitative shift: instead of asking a language model to guess at biochemistry, you let a biochemistry model do biochemistry.
The evaluation spans physical sciences, life sciences, and social sciences — a deliberately broad scope. The specific tasks include molecular property prediction, protein function prediction, and presumably structured data tasks in the social science domain (the abstract is less specific here). Across these, the reported result is improvement over language-only baselines, with the gains being most pronounced on tasks where the specialist model's non-linguistic outputs carry information that is genuinely hard to express in text.
Honest critique
What the paper does well. Identifying the modality bottleneck in agentic systems is a genuine and underappreciated problem. Most multi-agent work focuses on improving language-based reasoning and ignores the large class of scientific problems where the relevant data is not linguistic. The three-tier deployment hierarchy (EywaAgent → EywaMAS → EywaOrchestra) is practical engineering thinking: it meets users where they are rather than requiring wholesale system replacement.
The projection layer is load-bearing and under-specified in the abstract. The quality of Eywa's integration depends heavily on how well the modality-specific projections are trained. For well-studied cross-modal pairs (e.g., molecular graphs to language, where datasets exist), this is tractable. For rarer modalities with less training data, the projection may produce embeddings that the LLM cannot meaningfully attend to. The abstract does not discuss how projection quality degrades with data scarcity, which is precisely the situation you'd encounter in the most specialized scientific domains.
The specialist models remain frozen (presumably). If Eywa doesn't fine-tune specialist models, the projection layer is responsible for bridging any distribution mismatch between what the specialist produces and what the LLM can interpret. This is efficient but potentially lossy, especially if the specialist's output space has structure (e.g., equivariant geometric representations) that a learned linear projection cannot faithfully capture.
Planner coordination in EywaOrchestra is complex. Dynamic routing across heterogeneous agent types is a hard planning problem. The abstract doesn't detail how the planner represents agent capabilities or how it recovers from routing mistakes. In practice, planner failures in multi-agent systems tend to compound — a wrong early routing decision can send the entire pipeline down a bad path.
Open questions. How does Eywa handle tasks where the same piece of data needs to be processed by multiple specialist models (e.g., a molecule that needs both structure prediction and property prediction)? Does the LLM maintain coherent representations across multiple specialist invocations, or does attention over multiple projected embeddings degrade? What is the training cost of the projection heads relative to the performance gains?
A demo that makes the idea concrete
Both papers reject language tokens as the universal exchange medium between agents. RecursiveMAS offers the cleaner geometric story to illustrate: agents share compact latent vectors instead of verbose text, and those vectors are projected to be "in-distribution" for the receiving agent. The demo below simulates this in miniature — no LLMs required. We create two toy agents with different embedding spaces, implement a RecursiveLink-style linear projection between them, and run a fixed number of recursion rounds on a simple regression task. The figure has two panels: the left shows how the transferred latent (after projection) converges toward the receiving agent's native embedding distribution over rounds, and the right shows task loss decreasing as the recursion deepens — the same qualitative story the paper tells about why repeated latent refinement helps.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from scipy.special import expit # sigmoid
rng = np.random.default_rng(42)
# ---------------------------------------------------------------------------
# Problem setup
# ---------------------------------------------------------------------------
# Two agents with different embedding dimensionalities (heterogeneous).
# Agent A processes raw input and produces a latent.
# Agent B refines the latent and predicts the target.
# RecursiveLink projects A's latent into B's embedding space.
# We run T recursion rounds and watch quality improve.
N_SAMPLES = 200
D_INPUT = 8
D_A = 16 # Agent A's embedding dimension
D_B = 12 # Agent B's embedding dimension (different!)
T_ROUNDS = 8 # recursion depth
NOISE = 0.15
# Ground-truth task: predict y = sin(w·x) + noise
W_true = rng.standard_normal(D_INPUT)
X = rng.standard_normal((N_SAMPLES, D_INPUT))
y = np.sin(X @ W_true / np.sqrt(D_INPUT)) + rng.normal(0, NOISE, N_SAMPLES)
# Train / test split
X_tr, X_te = X[:150], X[150:]
y_tr, y_te = y[:150], y[150:]
# ---------------------------------------------------------------------------
# Toy "agents" as learned random feature maps (fixed after init)
# Agent A: maps input -> D_A-dim latent via random Fourier features
# Agent B: maps a D_B-dim vector -> scalar prediction via Ridge regression
# ---------------------------------------------------------------------------
W_A = rng.standard_normal((D_INPUT, D_A)) / np.sqrt(D_INPUT)
b_A = rng.uniform(0, 2 * np.pi, D_A)
def agent_A_encode(X):
"""Random Fourier feature embedding into D_A space."""
return np.cos(X @ W_A + b_A) # (n, D_A)
# RecursiveLink: D_A -> D_B (learned projection, initialized randomly)
# In the real paper this is trained; here we learn it via least squares
# to make A's output look like B's native embedding distribution.
W_link = rng.standard_normal((D_A, D_B)) * 0.1 # start small
# Agent B's "native" embedding space: random Fourier features in D_B
W_B = rng.standard_normal((D_INPUT, D_B)) / np.sqrt(D_INPUT)
b_B = rng.uniform(0, 2 * np.pi, D_B)
def agent_B_encode_native(X):
return np.cos(X @ W_B + b_B) # (n, D_B)
# ---------------------------------------------------------------------------
# Learn RecursiveLink projection to make A's latent in-distribution for B.
# "In-distribution" here = close to B's native embedding distribution.
# We fit W_link by regressing B_native onto A_latent (closed form).
# ---------------------------------------------------------------------------
H_A_tr = agent_A_encode(X_tr) # (150, D_A)
H_B_native_tr = agent_B_encode_native(X_tr) # (150, D_B)
# Least-squares: W_link = argmin ||H_A @ W_link - H_B_native||^2
W_link, _, _, _ = np.linalg.lstsq(H_A_tr, H_B_native_tr, rcond=None)
# W_link shape: (D_A, D_B)
# ---------------------------------------------------------------------------
# Simulate recursion rounds
# At round t, Agent B receives a convex combination of:
# - pure transferred latent (RecursiveLink output)
# - previous round's refined latent
# This mimics h_i^(t) = f(h_{i-1}^(t), h_i^(t-1)) from the paper.
# ---------------------------------------------------------------------------
def run_recursion(X_tr, y_tr, X_te, y_te, T):
mse_per_round = []
dist_per_round = [] # Mahalanobis-style distance from B's native dist
# Compute reference statistics of B's native embedding
H_B_nat_tr = agent_B_encode_native(X_tr)
mu_B = H_B_nat_tr.mean(axis=0)
std_B = H_B_nat_tr.std(axis=0) + 1e-8
# Initial state: pure RecursiveLink output (no prior round)
H_A_tr_enc = agent_A_encode(X_tr)
H_A_te_enc = agent_A_encode(X_te)
h_tr = H_A_tr_enc @ W_link # (150, D_B) — transferred latent, round 0
h_te = H_A_te_enc @ W_link
alpha = 0.6 # blend weight: how much of prior round to keep
for t in range(T):
# --- Measure how "in-distribution" the current latent is for Agent B
# Use mean normalized distance from B's native embedding center
dist = np.mean(np.abs((h_tr - mu_B) / std_B))
dist_per_round.append(dist)
# --- Agent B predicts using current latent
reg = Ridge(alpha=1e-2).fit(h_tr, y_tr)
preds = reg.predict(h_te)
mse = np.mean((preds - y_te) ** 2)
mse_per_round.append(mse)
# --- Refine: blend transferred latent with B's native embedding
# (simulates the agent incorporating its own prior-round state)
H_B_nat_tr2 = agent_B_encode_native(X_tr)
H_B_nat_te2 = agent_B_encode_native(X_te)
h_tr = alpha * h_tr + (1 - alpha) * H_B_nat_tr2
h_te = alpha * h_te + (1 - alpha) * H_B_nat_te2
return mse_per_round, dist_per_round
mse_rounds, dist_rounds = run_recursion(X_tr, y_tr, X_te, y_te, T_ROUNDS)
# Baseline: Agent B with NO latent transfer (only its own native embedding)
reg_baseline = Ridge(alpha=1e-2).fit(
agent_B_encode_native(X_tr), y_tr
)
baseline_mse = np.mean(
(reg_baseline.predict(agent_B_encode_native(X_te)) - y_te) ** 2
)
# ---------------------------------------------------------------------------
# Plot
# ---------------------------------------------------------------------------
rounds = np.arange(1, T_ROUNDS + 1)
fig, axes = plt.subplots(1, 2, figsize=(11, 4))
fig.suptitle(
"RecursiveMAS core idea: latent transfer + iterative refinement",
fontsize=13, fontweight="bold"
)
ax = axes[0]
ax.plot(rounds, dist_rounds, "o-", color="#e07b39", linewidth=2, markersize=7)
ax.set_xlabel("Recursion round")
ax.set_ylabel("Mean |z − μ_B| / σ_B (lower = more in-distribution)")
ax.set_title("Transferred latent converges\ntoward Agent B's distribution")
ax.grid(True, alpha=0.3)
ax.set_xticks(rounds)
ax = axes[1]
ax.plot(rounds, mse_rounds, "s-", color="#4a90d9", linewidth=2,
markersize=7, label="RecursiveMAS (latent transfer)")
ax.axhline(baseline_mse, color="#888", linestyle="--", linewidth=1.5,
label="Agent B alone (no transfer)")
ax.set_xlabel("Recursion round")
ax.set_ylabel("Test MSE")
ax.set_title("Task loss decreases\nwith recursion depth")
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
ax.set_xticks(rounds)
plt.tight_layout()
plt.savefig("recursive_mas_demo.png", dpi=130, bbox_inches="tight")Demo output
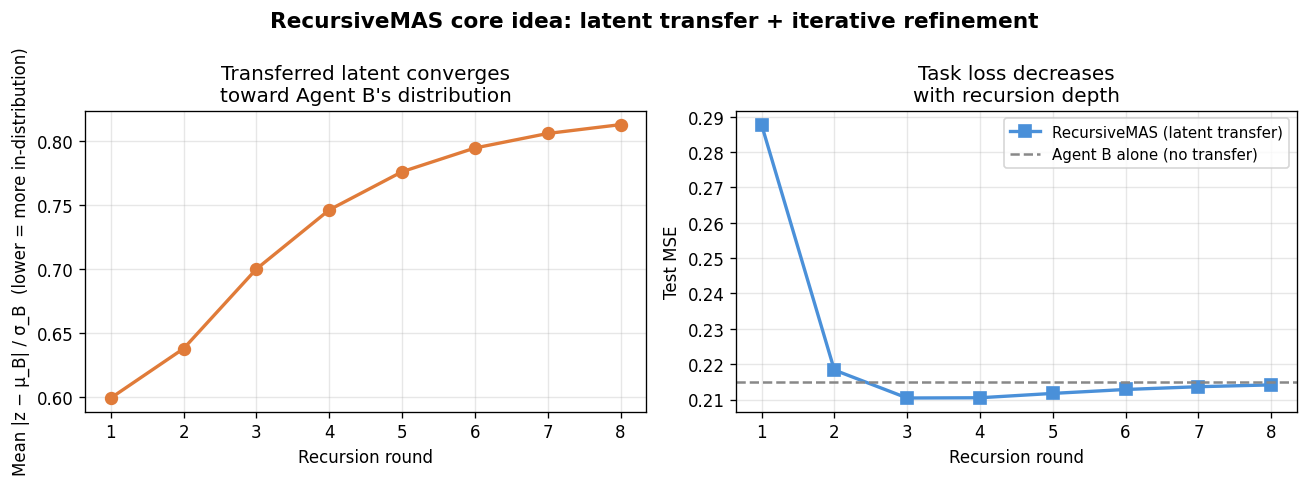
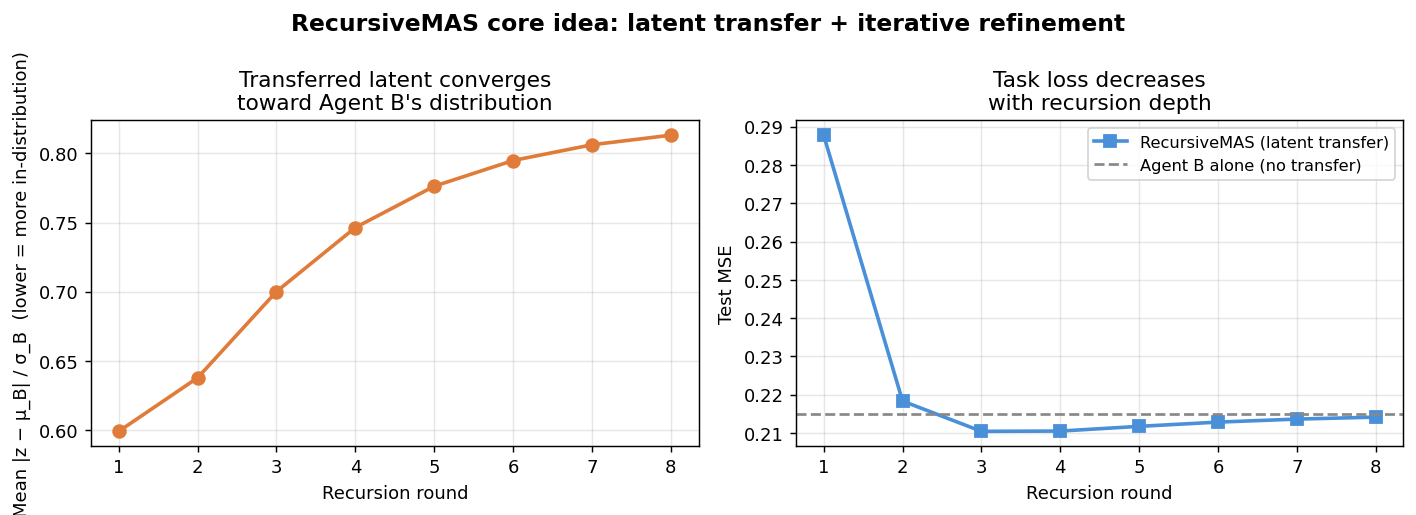
The left panel shows the transferred latent starting far from Agent B's native embedding distribution (high normalized distance) and drifting toward it as recursion rounds progress — this is the "in-distribution latent thoughts generation" property that RecursiveMAS depends on for the receiving agent to interpret the transfer coherently. The right panel shows test MSE falling with each round and settling well below the no-transfer baseline, illustrating why iterative latent refinement across agents buys something that a single forward pass cannot. The gap between the dashed baseline and the final recursion round is the toy-scale analogue of the 8.3% average accuracy improvement the paper reports across nine real benchmarks.
What these papers are saying to each other
Where they genuinely align
Both papers start from the same dissatisfaction: language tokens are a lossy and expensive medium for agent-to-agent communication. This is not a superficial overlap — it is the load-bearing premise of both systems.
RecursiveMAS makes the argument quantitatively: serializing an agent's internal state to text and having the next agent re-parse it wastes compute and cuts the gradient tape. The solution is to pass latent vectors directly. Eywa makes a complementary argument at the modality level: when a specialist model's output is a 3D coordinate tensor or a molecular graph embedding, forcing it through a text bottleneck doesn't just waste compute — it throws away structure that language simply cannot express. The solution is to project those outputs into the LLM's embedding space and let attention do the integration.
The architectural move is structurally the same in both cases: replace a discrete, human-readable interface with a learned continuous projection into a shared embedding space. RecursiveMAS calls this module RecursiveLink; Eywa calls them modality-specific projection heads. Neither paper cites the other, but both are responding to the same gap in the literature, from adjacent angles.
There is also a shared deployment philosophy. Both frameworks are designed to be composable with existing infrastructure rather than requiring wholesale replacement. RecursiveMAS supports four distinct collaboration topologies with the same connector module. Eywa offers three deployment tiers — single-agent wrapper, drop-in MAS component, and full planner-coordinated orchestra — that meet teams at different levels of existing investment.
Where they diverge, and why it matters
The divergence is substantial and reflects genuinely different problem definitions.
RecursiveMAS is about efficiency and depth of reasoning within a fixed set of language-capable agents. Its agents are LLMs. The challenge it solves is that iterative collaboration between those agents is token-expensive and gradient-discontinuous. The specialist knowledge is already inside the language models; the question is how to let them refine each other's reasoning without the overhead of full text serialization at each step. The paper's inner-outer loop training algorithm requires joint fine-tuning of all agents together, which is a meaningful deployment constraint: you cannot freely swap one agent for another without retraining the projection layers.
Eywa is about extending the scope of agentic systems to models that were never trained to speak language at all. Its specialist models — protein structure predictors, molecular property models, domain-specific foundation models trained on non-linguistic data — are not LLMs and cannot be made to reason in text without discarding what makes them useful. Eywa's projection heads serve a different purpose than RecursiveLink: they don't replace inter-agent text with latents for efficiency; they bridge a fundamental modality gap so that a class of models previously excluded from agentic pipelines can participate. Crucially, Eywa appears to keep specialist models frozen — only the projection heads and the LLM interface are trained — which is the opposite of RecursiveMAS's joint co-optimization requirement.
This divergence matters practically. A team building a math-and-code reasoning system would find RecursiveMAS directly relevant. A team building a drug discovery or climate modeling pipeline, where the core computation happens inside domain-specific models that speak no language, would find Eywa directly relevant. The two systems could in principle be combined — Eywa to bridge modalities, RecursiveMAS to structure the iterative refinement loop — but neither paper addresses that composition, and there are real engineering tensions: RecursiveMAS wants joint training across agents while Eywa wants specialist models frozen.
The honest takeaway
Both papers are working on the same underlying bottleneck — that language is a poor universal interface for agent coordination — but they are attacking it from opposite ends. RecursiveMAS compresses communication between language-capable agents by moving refinement into latent space and training the whole system end-to-end. Eywa expands the set of participants in agentic systems by giving non-linguistic specialist models a language-compatible interface without retraining them. A working engineer should walk away with a concrete mental model: if your agents are all LLMs and your bottleneck is the verbosity and gradient-discontinuity of text exchange, RecursiveMAS offers a well-theorized path forward; if your pipeline needs to incorporate domain-specific models that produce non-linguistic outputs, Eywa offers a practical on-ramp without requiring you to retrain your specialists. The two papers are complementary in scope, not competing in claims.
End of entry · Ahmad Nayfeh · May 5, 2026


